

[Paper Notes] Contact-Grounded Policy: Dexterous Visuotactile Policy with Generative Contact Grounding
Published:
TL;DR
Contact-Grounded Policy (CGP) is a supervised visuotactile diffusion policy for contact-rich dexterous manipulation. Its main argument is that tactile prediction becomes useful for control only when it is grounded in what the low-level compliance controller can actually execute. CGP therefore predicts future actual robot states and tactile feedback together, then maps each predicted state-contact pair into a target robot state for the controller.
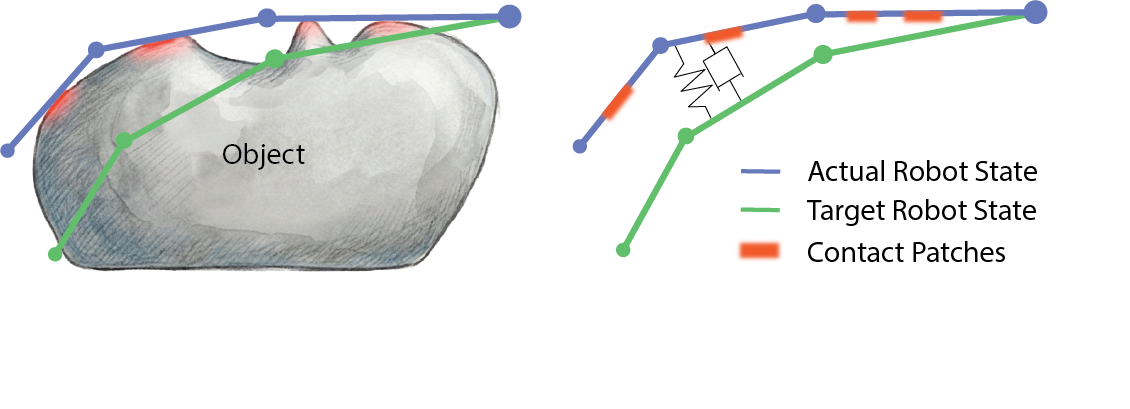
The figure captures the control issue: actual robot state, target robot state, and contact patches are coupled through the compliant controller. CGP learns this coupling from demonstrations, which turns contact from an observed consequence into a realizable control target.
Paper Info
The paper is “Contact-Grounded Policy: Dexterous Visuotactile Policy with Generative Contact Grounding” by Zhengtong Xu, Yeping Wang, Ben Abbatematteo, Jom Preechayasomboon, Sonny Chan, Nick Colonnese, and Amirhossein H. Memar. It is listed as Robotics: Science and Systems (RSS), 2026 on the project page. The paper is available as arXiv:2603.05687, with project materials at contact-grounded-policy.github.io.
Core Argument
Dexterous manipulation is hard because success depends on multi-point contacts that evolve continuously. A hand may need to roll, pinch, press, wipe, twist, or delicately hold an object while contact points migrate across fingers and palm. These interactions depend on object geometry, friction, slip, compliance, and partial observability.
Many visuomotor policies predict kinematic targets such as end-effector poses, hand joint angles, or action chunks. In contact-rich tasks, a geometrically plausible hand target can still slip, apply the wrong force, break a fragile object, or lose a contact patch. The paper’s key critique is that feeding tactile observations into a policy, or predicting tactile signals as an auxiliary objective, does not ensure that the resulting contact can be realized by the controller.
CGP frames contact under a fixed tactile sensor and compliance controller as a triplet: actual robot state, tactile feedback, and target robot state. The gap between target and actual state is meaningful because contact forces can push the robot away from its commanded reference. During contact, that deviation encodes physical interaction, so CGP learns the setup-specific mapping:
actual robot state + tactile feedback -> target robot state
This is the paper’s main mechanism. The diffusion model proposes future state-contact evolution, and the learned contact-consistency mapping turns that evolution into controller references.
Method
CGP has two coupled modules. First, a conditional diffusion model predicts a short-horizon trajectory of future actual robot states and future tactile latents. Second, the contact-consistency mapping converts every predicted actual-state/tactile pair into an executable target state:
predicted actual state + predicted tactile latent -> target robot state
At inference time, CGP runs in a receding-horizon loop. The diffusion model predicts the next 16 steps of actual state and tactile feedback, the mapper converts them to target states, and the controller executes 8 steps before replanning. Rollout runs at 5 Hz with 8 DDIM denoising steps.
The tactile stream is compressed before diffusion. In simulation, the Tesollo DG-5F hand uses dense tactile arrays with 768 sensing points, each reporting a 3D force vector. On hardware, each Digit360 fingertip sensor produces RGB tactile images. CGP uses a KL-regularized VAE: dense tactile arrays use a 1D ResNet-style encoder/decoder and a 32-dimensional latent, while four Digit360 sensors use shared 2D ResNet-style per-sensor encoders/decoders and an 80-dimensional latent, or 20 dimensions per sensor. The KL term matters because lower reconstruction error without KL can produce a less structured latent space and worse rollout performance.
Evaluation
The evaluation spans simulation and real hardware. In simulation, the robot is a UR5 arm with a Tesollo DG-5F five-finger 20-DoF hand; the arm uses operational-space impedance control, the hand uses joint-space PD control, and tactile sensing comes from dense whole-hand tactile arrays. On hardware, the system uses a Franka Panda arm, an Allegro V5 four-finger 16-DoF hand, four Digit360 fingertip tactile sensors, and two RGB views: an agent view and a wrist view. Demonstrations are collected through Meta Quest 3 VR teleoperation in simulation and through OptiTrack mocap plus an instrumented glove on the real robot, with retargeting and a shared compliant control stack.
The task suite is deliberately contact-heavy: simulated in-hand box flipping, simulated fragile egg grasping, simulated dish wiping, real jar opening, and real in-hand box flipping. CGP is compared against a visuomotor diffusion policy using vision and robot state, and a visuotactile diffusion policy using vision, robot state, and tactile observations without contact grounding.
| Task | CGP | Visuotactile DP | Visuomotor DP |
|---|---|---|---|
| In-Hand Box Flipping (Sim) | 66.0% | 58.0% | 53.2% |
| Fragile Egg Grasping (Sim) | 74.8% | 70.0% | 53.2% |
| Dish Wiping (Sim) | 58.4% | 43.6% | 42.4% |
| Jar Opening (Real) | 93.3% | 66.7% | 73.3% |
| Real In-Hand Box Flipping | 80.0% | 60.0% | 60.0% |
The largest gains appear where contact evolution is central: dish wiping, jar opening, and real in-hand flipping. The time-aligned predicted and observed tactile visualizations strengthen the result because CGP predicts tactile trajectories, converts them into controller targets, and then observes future tactile frames that closely match the earlier predictions. That makes the tactile prediction part of the executed behavior, not merely an auxiliary forecast.
The paper also isolates the contact-consistency mapping with a hand-configuration prediction task using 150 teleoperated grasping episodes, 4114 frames, and 11 objects in simulation. The strongest setting combines state and tactile input, a ResNet-style tactile encoder, and residual target prediction. MAE drops from 8.80 in absolute mode to 5.94 in residual mode; removing either modality hurts, with 10.64 for state-only residual prediction and 12.15 for tactile-only residual prediction even with the ResNet encoder. This supports the central hypothesis: tactile feedback and actual state together encode the controller-realizable contact structure.
Limitations
The main limitation is specificity. The contact-consistency mapping is tied to a particular hand, tactile sensor layout, and compliance controller; changing the sensor type, controller gains, or hand embodiment may require retraining or adaptation. The evaluation is also single-task: each policy is trained and evaluated on one task, so the paper does not yet establish cross-task transfer of contact knowledge across different objects, objectives, and contact regimes.
CGP also depends on specialized tactile hardware. Digit360 fingertip sensors are powerful, but broader deployment would need more common tactile sensing or robust cross-sensor adaptation. Finally, the policy is supervised from demonstrations. This avoids reward engineering, while still leaving scale dependent on collecting diverse contact-rich demonstrations.
Takeaways
CGP is worth reading because it clarifies a useful principle for dexterous manipulation: contact prediction should be shaped by the controller that must realize it. The reusable recipe is compact: represent contact through actual state, tactile feedback, and target state; predict future actual state and tactile feedback together; learn the contact-consistency mapping into executable controller references; compress tactile observations into a KL-regularized latent before diffusion; and treat the compliance controller as part of the learned contact model.
My taxonomy for this paper:
Supervised Visuotactile Diffusion Policy / Contact-Grounded Dexterous Manipulation / Controller-Aware Tactile Prediction